最近参加了ECUG大会,其中有两个分享是有关微服务的,一个是CODING的微服务拆分,一个是网易的服务网格实践,那我对这些也有些思考,今天我们来聊一聊到底要不要选择serviceMesh架构的,正确的来说是关于服务网格的架构,但是这种架构也可以说是微服务架构的一种变体。时间是40分钟,虽然时间不长,但是还是感觉受益匪浅。下面我将对我的认知和今天学到的东西进行叙述,欢迎大家来评论讨论,也可以加我的微信进行讨论。
1 为什么要拆服务?
这个问题,其实你去百度和谷歌搜索,一定会有一箩筐的问题,但是我感觉废话太多,下面说下我对这个问题的看法。
单体的痛点
- 编译、启动、扩容时间长
- 开发冲突
- 耦合性高
- 代码冗余复杂
- 资源利用率低
- 业务模块复用率低
- 等等
微服务的优点是什么?(微服务让我们更好的应用设计模式!)
- 低耦合、高内聚(单一职责)
- 业务边界清晰、复用性高(迪米特原则)
- 面向接口的编程,不依赖细节,(依赖倒转原则)
- 易开发、易维护、易发布(scrum小步快跑)
- 动态伸缩,资源利用率更高(节省成本)
- 针对业务使用不同的技术(最优方案)
微服务的缺点呢?
- 运维成本高(感谢容器拯救我们,但是大量服务还是费神费力)
- 分布式导致应用复杂性提高(出现很多让你想不到bug)
- 跟踪费力(感谢链路追踪解决这个问题)
- 排查费力(感谢日志分析平台)
- 需要开发拥有一定实力
以上就是我现在想到的一些想法,如有不足,欢迎补充
2 关于服务粒度与业务边界
吴海黎今天说他们之前在拆一个北京的电商项目时,由于没有经验,也就是没有微服务拆分的内功(下面会讲,先卖个关子),对微服务进行了盲目的拆分,根据数据库表结构进行拆分,基本上一张表一个微服务,导致少量程序猿维护大量的细粒度微服务,这种情况虽然不多见,但是这个问题确实是很多在开发者在拆服务时候会遇到的一个问题。微服务的拆分不光要根据业务边界进行拆分,同时也跟公司的组织架构有关系。
那么如何进行服务拆分?
如果在一个没有对服务拆分经验的团队来说,那么最好的方案就是根据模块拆分,这样可以保证60%的情况下不会出现一些太大的问题,比如电商行业的话就是用户、商品、订单、库存等
如果恰好你的团队有对服务拆分有经验的童鞋,那就好办太多了,高呼一句DDD万岁!DDD本质上是一种面向对象的思维(真正的),习惯了对数据CURD和MVC模型的童鞋是很难转变过来的。因为DDD实在是太抽象了,很多时候我们都是云里雾里,我现在也只是略微清晰,需要慢慢的去消化,进步。现在开始进行第一步
2.1 场景分析
- 解读用户视角,用例分析,用户旅程分析
- 探索业务领域的场景,业务场景分析
- 产出
场景、用例、子域依赖关系 - 参与者:
产品经理、需求分析人员、架构师、开发组长和测试组长。
2.2 业务建模
- 对业务和问题域分析
- 建立领域模型
- 向上微服务边界划分设计
- 向下聚合指导实体对象设计
- 产出
类图、顺序图、状态图等静动态分析结果 - 参与者:
领域专家,产品经理、需求分析人员、架构师、开发组长和测试组长。
推荐使用事件风暴,不懂就去百度它,这是一种非常高效的建模方式,并且很有意思。这种方法是一种事件优先的思想,把发生的事情作为设计的首要考虑目标。也就是说是一种事件驱动的方式,那么怎么做呢?
- 捕捉
领域事件,重现事件发生顺序,用橙色标签表示,比如用户信息已查询 - 找到事件的来源,用蓝色标签表示,比如查找用户信息
- 找出领域事件属性,用黄色标签表示,多来源可以多颜色,比如输入输出
- 寻找业务
领域聚合实体,用绿色标签,比如事件触发者
2.3 架构设计
下面就说下DDD中的分层架构,这块我也只是了解皮毛,并没有使用这种4层架构进行服务开发过,工作中还是使用MVC这种贫血模型更多一些,这里可能也是我的一个欠缺点,后期也会补一补。。
- 表示层(你就理解为Controller层好了,对外提供接口,网络传输边界)
- 应用层(观察者模式,领域对象协调任务,用户用例操作,这步分布式调用)
- 领域层(实体,值,聚合对象,业务逻辑实现)
- 基础层(接口管理,数据库持久化)
看看这种架构,再看看MVC的架构,这种DDD的架构是严格按照面向对象的思想去实现的,我们使用MVC模式其实本质上就是扛着面向对象的大旗干着耍流氓的事。
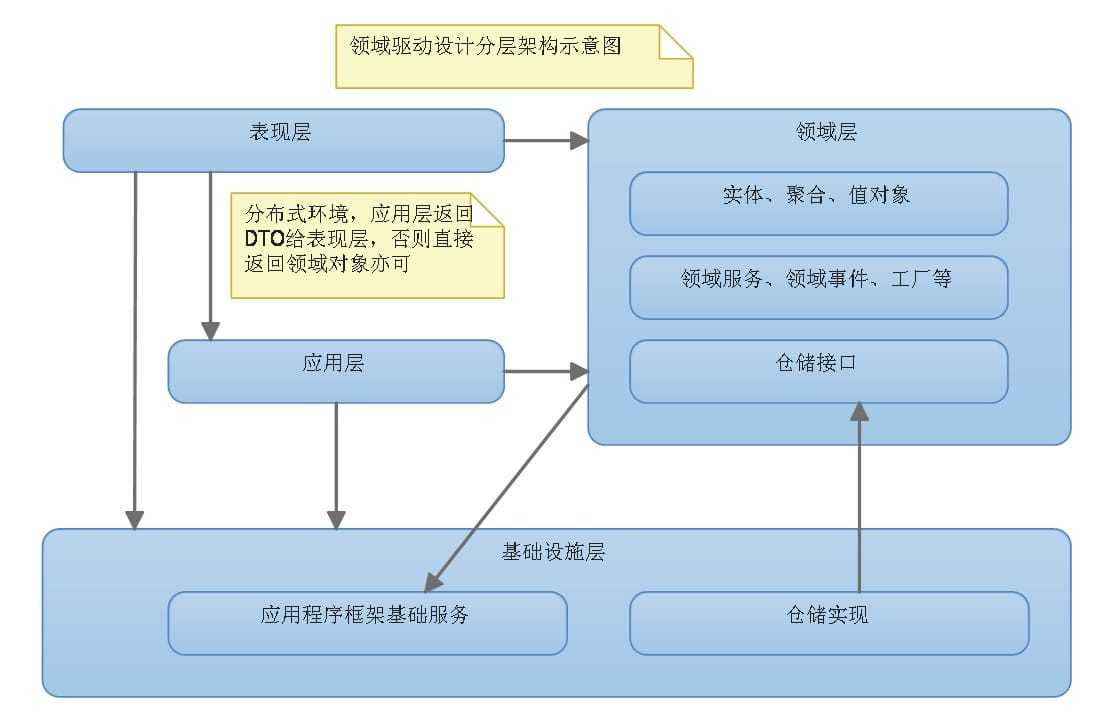
之前说过微服务的架构不光跟业务边界有关系,还跟公司的组织架构有关系。这句话是什么意思呢?让我们先来了解下康威定律
2.4 康威定律(摘自网络)
通俗的来讲:产品必然是其(人员)组织沟通结构的缩影。比如下方是国际大厂的组织架构
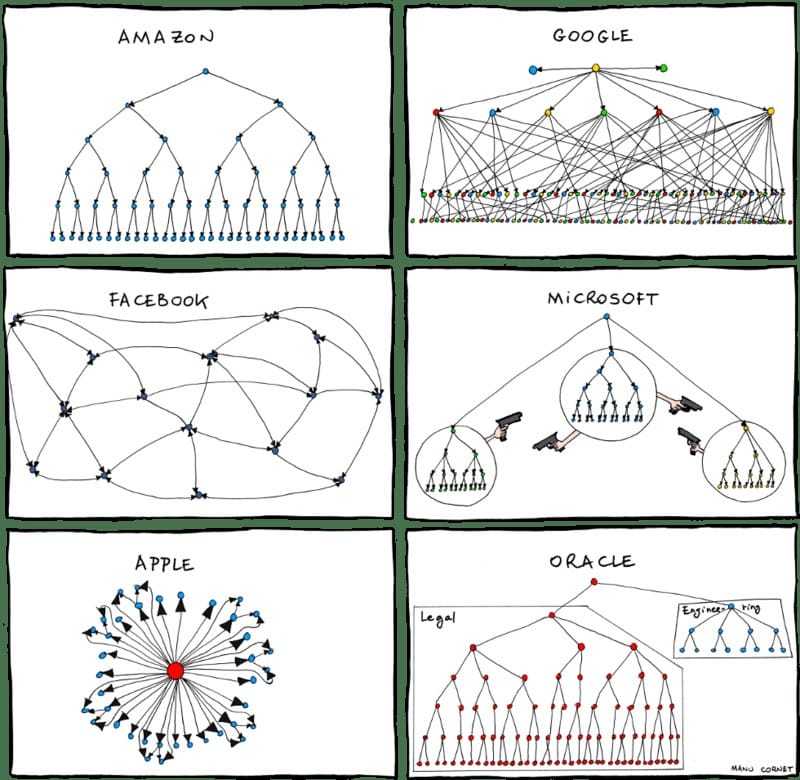
康威定律可谓软件架构设计中的第一定律,起初只是在杂志上的发表,后经过《人月神话》这本软件界圣经的引用,并命名为康威定律(Conway’s law),因此得以推广。只通过简单的描述可能无法理解康威定律的精髓所在,原文中康威定律可总结为四个定律:
- 第一定律 组织沟通方式会通过系统设计表达出来。
- 第二定律 时间再多一件事情也不可能做的完美,但总有时间做完一件事情。
- 第三定律 线型系统和线型组织架构间有潜在的异质同态特性。
- 第四定律 大的系统组织总是比小系统更倾向于分解。
2.4.1 第一定律
组织沟通方式决定系统设计。
这条定律重点是讲组织架构和沟通对系统设计的影响。组织的沟通和系统的设计之间紧密相连,特别是复杂系统,解决好人与人的沟通才能有一个更好的系统设计。
《人月神话》中总结出了随着人员的增加沟通成本呈指数增长的规律:沟通成本 = n(n-1)/2
这也是为什么互联网公司都追求小团队的原因之一。沟通的问题会带来系统设计的问题,进而影响整个系统的开发效率和最终产品结果。
2.4.2 第二定律
时间再多一件事情也不可能做的完美,但总有时间做完一件事情。
人手永远是不够的,事情永远是做不完的,但可以一件一件来。这不就是软件行业中“敏捷开发”模式所解决的问题吗。面对这样的状况,敏捷开发可以做到不断迭代、持续交付、快速验证和反馈,并持续改进。
再牛的开发也会写出bug,再全面的测试覆盖率也无法测出所有的问题。解决方案不是消灭这些问题,是容忍一些问题的存在,然后通过适当的设计(冗余、监控、高可用设计)当问题发生时能够快速解决。
几个开发人员的小公司,去追求微服务、去追求中台架构,这是追求完美吗?不是,是找死。
好的架构不是买来的,也不是设计出来的,而是根据业务落地生根长期演化来的。
2.4.3 第三定律
线型系统和线型组织架构间有潜在的异质同态特性。
这一定律是第一定律的具体应用。想象一下如果公司的组织架构是这样的:
团队是分布式,每个团队都包含产品、研发、测试、运维等角色。而此时系统是单块的,项目沟通和协调的成本是巨大的,弄不好还会打起来。
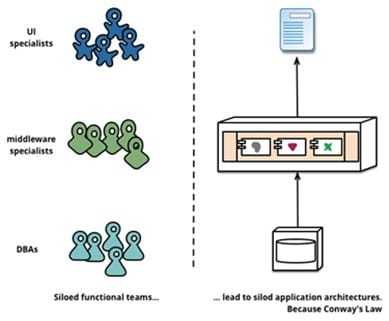
如果将单块的系统拆分成微服务,每个团队负责自己的部分,对外提供对应的接口即可,互不干扰。系统效率将得到提升。这与软件设计中的高内聚、低耦合是相通的。
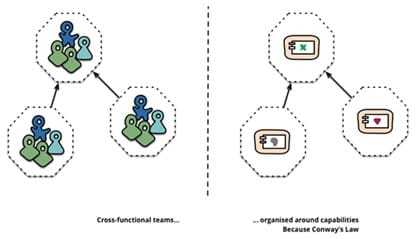
直白的说就是想要什么的系统就搭建什么样的团队,有什么样的团队就搭建什么样的系统。需要前后端分离的系统就搭建前后端分离的团队,反之,拥有前后端分离的团队,可以设计前后端分离的系统。当然,如果能统筹管理,拥有重组团队或设计系统架构的权利,那就再好不过了。通常情况下让两者形成1:1的映射关系,更加高效。
2.4.4 第四定律
大的系统组织总是比小系统更倾向于分解。
“话说天下大势,分久必合,合久必分。”系统越复杂,越需要增加人手,人手越多,沟通成本也呈指数增长。分而治之便是大多数公司选择的解决方案。分不同的层级,分不同的小团队,让团队内部完成自治理,然后统一对外沟通。
说到这,你是不是想起来秦始皇的中央集权郡县制?
3 技术选型
话说这两天的大会上,CODING和网易都在分享服务网格在他们那里落地的实践。这个点怎么说呢?
之前我是调研过一阵子这种架构,概念很棒,将服务治理等技术从代码中剥离出来,使得我们的业务代码更干净,无侵入,更专注于业务逻辑。
但是目前开源社区主推的两种技术貌似都不是很成熟,它们分别是Istio 和 Linkerd。最有意思的是CODING选的是Linkerd,网易选的是Istio。那么我怎么看这个点呢,我从各个维度来给你讲讲。
3.1 要不要使用服务网格架构
首先我们要讨论为啥要使用服务网格。是不是真的有多语言业务痛点。如果你的业务都是Java生态的,那先别凑热闹,SpringCloud+Dubbo已经很香了。该有的都有了,你要的还给你更新,包括国内的形式,SpringCLoud跟Alibaba的py交易,已经是让java的微服务开发方便的不能再方便了。那真正需要考虑服务网格这种架构的是那些有异构服务业务的公司。
比如AI行业,因为AI的服务化99%都是Python写的,我对python的服务治理真的是煞费苦心,所以我其实挺希望sidecar可以快速崛起,但是现在还是太弱,虽然最近有一个小太阳graalVM在不断的升起,但是把python完美运行在jvm上可能还是需要个几年吧。
比如云行业,在google的golang(够浪)风靡全球,火爆2018的情况下,很多公司使用goolang去做一些跟网络相关的应用,毕竟golang的io模型是真的香,用golang去开发个网关啥的,在2018可能是随处可见的事。而且这个浪货能真正实现编译native应用,脱离虚拟机环境各种浪。
那么针对这种异构服务的情况,以往我们的做法是什么,通过http、thrift、grpc等方式解决服务调用的问题。但是在服务治理这,确实是让人脑仁疼,java的服务治理是spring都给集成好了,而其他语言,python、golang、nodejs的命运就是自己公司封装一套ioc框架来加载各种服务治理的插件,更有甚者直接生撸各种代码。但是服务网格的出现让异构服务眼前一亮,弄个sidecar把这些糟心的东西(控制面板和数据面板)都帮我弄好,这太方便了,老子终于也有java那种帝王般的待遇了。
但是,目前开源社区的服务网格产品都还不是很成熟,特别是Istio,底层使用iptables进行网络管理,尤其是架构中用来观察数据的Mixer简直就是性能杀手,让你的吞吐量一落千丈,我问网易的冯常健这个问题,他说他们线上直接把这个关了,用以前的链路追踪来代替它的观测性,不然根本不够它吃性能的。再加上经常出幺蛾子的Policy,如果不是大厂,没有专门的架构团队或者中间件团队来优化的话,还是死了这条心吧。再来说说Linkerd,它的性能可比Istio好上不少,但是在生态完整性上还是偏弱,没有Istio那么成熟,但对比我们传统应用也是有一定的延迟。最主要的是两者的易用性没那么高,并且目前来说还属于初创阶段,相当于5年前的k8s吧,玩一玩可以,如果不是大厂,没有精力去优化,那么还是等等吧。
之前网络上有很多拿istio、linkerd、zuul、gateway、nginx做路由转发性能测试,结果是gateway被吊打,这里要澄清下,别拿ab做测试了,gateway底层使用reactor netty,不支持HTTP1.0,什么年代了还用http1.0,这种也叫基准测试?你拿http1.1试试,吊打你们不?
再告诉你们一个点,springcloud sidecar其实挺香的。而且现在dubbo在多语言适配上走的越来越远了。所以使用这种sidecar进行服务网格实践也是一种不错的选择。
结论:
服务网格架构可以用,但是不要拘泥于形式,拘泥于框架
对于
istio和linkerd,我的建议是:大厂有精力维护优化,可以去搞。
小作坊的话,安心吃瓜,让大厂先去踩坑吧。
3.2 架构推荐
下面我将把我对微服务架构这块的相关选型经验进行输出(下文不会提高istio和linkerd)
我对各种组件的选型,本着下面的这个思想:
求稳,就走别人走过的路。用一些开源的,相对标准的技术,而不是一味的求新求小众。有时可能小众组件仅突出一个点,但是给你带来的却是毁灭级的无便携和不可维护。
3.2.1 服务注册与发现
- zoookeeper
- eureka
- consul
- etcd
- coreDNS
- nacos
| zookeeper | eureka | consul | etcd | coreDNS | nacos | |
|---|---|---|---|---|---|---|
| CAP | CP | AP | CP | CP | - | CP/AP |
| 一致性算法 | paxos | - | Raft | Raft | - | Raft |
| kv存储服务 | 支持 | 支持 | 支持 | 支持 | - | 支持 |
| 监听 | 支持 | 支持 | 支持 | 支持 | 不支持 | 支持 |
| 健康检查 | TCP/心跳 | 心跳 | TCP/HTTP/gRpc | 心跳 | - | TCP/HTTP/心跳 |
| 雪崩保护 | 无 | 有 | 无 | 无 | 无 | 有 |
| 自动注销 | 支持 | 支持 | 不支持 | 支持 | 不支持 | 支持 |
| 访问协议 | TCP | HTTP | HTTP/DNS | HTTP/gRpc | DNS | HTTP/DNS |
| 多数据中心 | 不支持 | 支持 | 支持 | 支持 | 不支持 | 支持 |
| 跨注册中心同步 | 不支持 | 不支持 | 支持 | 支持 | 不支持 | 支持 |
| 推荐 | 不推荐 | 不推荐 | 推荐 | 不推荐 | 不推荐 | 推荐 |
| 原因 | 功能少,不够灵活 | 停止维护,不一致 | 推荐,社区活跃 | 不推荐,不适合 | 不推荐,除非k8s那套 | 功能强大,社区活跃 |
注册中心要解决问题是下面这几点:
- 解耦
- 服务动态伸缩
- 服务注册
- 服务发现
- 服务监控状态
所以我们在选型的时候要考虑下面这几点:
- 规模性,大规模选ap,小规模选cp
- 成熟度,功能是否能满足
- 维护成本,社区是否活跃,出现问题是否可以快速解决
- 性能,使用时是否有性能问题
- 稳定性,是否稳定,怎么选主,网络不稳时怎么办
3.2.2 服务调用
- HTTP
- Thrift
- gRPC
- dubbo
| Thrift | gRPC | Dubbo | HTTP | |
|---|---|---|---|---|
| 协议 | tcp | http2 | tcp/http | http |
| 编码 | binary | protobuff(最优) | heisson/protobuff/http | http |
| 使用量 | 多 | 一般 | 多 | 多 |
| 安全控制 | 复杂 | 容易 | 复杂 | 容易 |
| 性能 | 中 | 高 | 高 | 低 |
| 成熟度 | 成熟 | 一般 | 成熟 | 成熟 |
| 多语言 | 支持 | 支持 | 部分支持 | 支持 |
| 社区活跃 | 不活跃 | 一般 | 活跃 | 活跃 |
| 服务体系 | 不完整 | 不完整 | 完整 | 完整 |
| 场景 | 长连接 | 长连接 | 长连接 | 短连接 |
| 推荐 | 不推荐 | 不推荐 | 推荐 | 推荐 |
| 原因 | 吃cpu | 没有亮点,需要IDL | 社区活跃陆续完善 | 实用度高 |
在对服务调用进行选型时我们主要考虑以下几点:
- 长连接还是短连接
- rpc是否规范
- 代码侵入是否严重
- 性能好不好
- 是否支持多语言
3.2.3 配置中心
- springcloud-conf
- apollo
- disconf
- nacos
| springcloud-config | apollo | disconf | nacos | |
|---|---|---|---|---|
| 静态配置 | 基于file | 支持 | 支持 | 支持 |
| 动态推送 | 支持 | 支持 | 支持 | 支持 |
| 多环境 | 基于git | 支持 | 支持 | 支持 |
| 多集群 | 支持 | 支持 | 支持 | 支持 |
| 多语言 | java | go/c++/python/php/java/.net/http | java | java/python/nodejs/http |
| 统一管理 | 基于git | 支持 | 支持 | 支持 |
| 本地缓存 | 不支持 | 支持 | 支持 | 支持 |
| 生效时间 | 手动 | 实时 | 实时 | 实时 |
| 自动推送 | 手动 | 自动 | 自动 | 自动 |
| 定时拉取 | 不支持 | 支持 | 依赖事件 | 待支持 |
| 用户权限 | 不支持 | 支持 | 支持 | 待支持 |
| 授权审核 | 不支持 | 支持 | 不支持 | 待支持 |
| 版本管理 | 基于git | 支持 | 不支持 | 支持 |
| 版本回滚 | 基于git | 支持 | 不支持 | 支持 |
| 规则检查 | 不支持 | 支持 | 不支持 | 待支持 |
| 灰度发布 | 不支持 | 支持 | 不支持 | 待支持 |
| 告警通知 | 不支持 | 支持 | 支持 | |
| 依赖 | eureka | eureka | zookeeper | 无 |
| 社区 | 不活跃 | 活跃 | 停止 | 活跃 |
| 推荐 | 不推荐 | 推荐 | 不推荐 | 推荐 |
| 原因 | 没界面,及其难用 | 功能强大,社区活跃 | 停止维护 | 前景好,社区活跃 |
配置中心要解决问题是下面这几点:
- 动态修改线上配置,基于开关开发
- 环境隔离
- 配置治理
- 驱动devops
3.2.4 限流熔断
- sentinel
- hystrix
- resilience4j
| sentinel | hystrix | resilience4j | |
|---|---|---|---|
| 隔离策略 | 信号量 | 线程池/信号量 | 信号量 |
| 熔断降级策略 | 响应时间、异常比例、异常数 | 异常比率 | 异常比率、响应时间 |
| 实时统计 | 滑窗(leapArray) | 滑窗(RxJava) | Ring Bit Buffer |
| 动态规则 | 多数据源 | 多数据源 | 有限支持 |
| 扩展性 | 多个扩展点 | 插件形式 | 接口形式 |
| 注解支持 | 支持 | 支持 | 支持 |
| 限流 | 基于QPS、调用关系 | 有限支持 | rate limiter |
| 流量整形 | 预热、匀速器、预热排队模式 | 不支持 | rate limiter |
| 自适应保护 | 支持 | 不支持 | 不支持 |
| 控制台 | 支持 | 不支持 | 不支持 |
| 社区 | 活跃 | 停止 | 一般 |
| 推荐 | 推荐 | 不推荐 | 推荐 |
| 原因 | 功能强大,社区活跃 | 停止维护 | 轻量级 |
限流熔断要解决问题是下面这几点:
- 服务高可用
- 单点故障导致链路瘫痪的情况
- 高并发时优先保证部分请求
3.2.5 链路追踪
听说es官方也出了一款开源的apm,不过还没调研
- zipkin
- pinpoint
- skywalking
- cat
- jaeger
| zipkine | pinpoint | skywalking | cat | jaeger | |
|---|---|---|---|---|---|
| 接入方式 | 拦截侵入 | 探针 | 探针 | 埋点侵入 | 拦截侵入 |
| agent到collector | http、MQ | thrift | gRPC | http、tcp | udp、http |
| opentrace | 支持 | 不支持 | 支持 | 不支持 | 支持 |
| 粒度 | 接口级 | 方法级 | 方法级 | 代码级 | 代码级 |
| 全局调用统计 | 不支持 | 支持 | 支持 | 支持 | 支持 |
| traceId查询 | 支持 | 不支持 | 支持 | 不支持 | 支持 |
| 报警 | 不支持 | 支持 | 支持 | 支持 | 不支持 |
| jvm监控 | 不支持 | 不支持 | 支持 | 支持 | 不支持 |
| ui丰富 | 低 | 高 | 中 | 高 | 中 |
| 数据存储 | es、mysql、cassandra、内存 | hbase | es、h2、tidb、shading-sphere | mysql、hdfs | es、kafka、cassandra、内存 |
| 扩展性 | 高 | 低 | 高 | 高 | |
| 多语言 | java、c#、go、php | java、php | java、c#、php、nodejs、python、go | Java、c、c++、python、nodejs、go | java、c#、go、php、python、nodejs、c++、ruby、rust |
| 性能损耗 | 中 | 高 | 低 | 中 | 中 |
| 社区 | 活跃 | 活跃 | 活跃 | 活跃 | 活跃 |
| 推荐 | 不推荐 | 不推荐 | 推荐 | 不推荐 | 不推荐 |
| 原因 | 代码侵入 | 性能影响大 | 强大,性能好 | 代码侵入 | 代码侵入但语言广 |
链路追踪要解决问题是下面这几点:
- 分布式调用链分析难
- 性能优化无从下手
3.2.6 监控告警
| prometheus+Grafana | open-falcon | zabbix | |
|---|---|---|---|
| 响应时间 | 快 | 快 | 快 |
| 图表 | 支持 | 支持 | 支持 |
| 自动发现 | 支持 | 支持 | 支持 |
| agent | 支持 | 支持 | 支持 |
| agentless | 不支持 | 不支持 | 支持 |
| snmp | 支持 | 支持 | 支持 |
| 外部脚本 | 不支持 | 支持 | 支持 |
| 插件 | 支持 | 支持 | 支持 |
| 插件创建 | 一般 | 简单 | 简单 |
| 告警 | 支持 | 支持 | 支持 |
| 告警收敛 | 灵活 | 简单 | 无 |
| 通知次数 | 不支持 | 支持 | 支持 |
| 存储 | 自己 | mysql | sql |
| 报表 | 支持 | 不支持 | 支持 |
| 采集范围 | 4 | 4 | 5 |
| 故障域 | 单组件 | 单组件 | 集成 |
| HA | HA | 单点 | 单点 |
| 配置 | 树形 | 模板 | 模板 |
这一块了解不是很清楚,估计运维可能理解更深一些,不过推荐使用prometheus+Grafana,因为后期一些业务监控可以直接写进prometheus(时序数据库),然后使用grafana进行可视化
3.2.7 日志中心
市面上基本只有两种splunk和elk
可能互联网公司中elk更多一些
3.2.8 服务网关
因为我们要在网关上做一些比如路由、权鉴、过滤、限流、熔断等操作。
所以我们会选择一些方便编程的网关,所以可能nginx系列不会在这里使用,而会在外层使用
这一块基本上就是zuul、spring cloud gateway,那么基于性能考虑,基本上就是gateway了
别再跟我说gateway性能没有zuul好了,请带着智商跟我说话!
3.2.9 服务编排
- docker-swarm
- k8s
这里就不多说了,选择k8s这种主流的准没错。但是由于k8s没有可视化界面。
我们采用了Rancher2,底层使用k8s来进行一些服务编排。
